When the Judge Gets Played: An Accidental Reward Hacking Case Study
TL;DR
While running a sweep of reward compositions for our paper on adaptive reward composition for reasoning models, we noticed something odd in one of our W&B runs: a single configuration — Qwen3-4B + GRPO with a HotpotQA-only QA reward (judged by GPT-4o) — abruptly shot up from ~5% to ~95% judged accuracy on a held-out SimpleQA evaluation at around training step 400. Every other model (Qwen3-8B, Llama-3.1-8B, Qwen3.5-9B-Base) and every other reward mix we tried looked completely normal. After digging in, we found the model had not gotten any better at SimpleQA at all — only 6.7% of its “correct” responses contained the reference answer. It had simply discovered a formatting style (headers, bullets, bold, “Key context:” sections) that systematically biases the GPT-4o judge into marking wrong answers as correct.
We later swapped the QA training judge for a simpler one and never reproduced this behavior in any subsequent model, data mix, or prompt configuration. We think the story is fun enough — and the diagnostic recipe useful enough — to document.
Where this came from
This wasn’t a study designed to look for reward hacking. It surfaced as an anomaly inside a broader sweep for our paper on adaptive reward composition for abstention-aware reasoning models (the AbReward project). The goal there is to make a model learn to abstain well on unanswerable questions while preserving its math reasoning and general QA ability, by composing multiple reward signals during RL:
- a math reward (DeepScaleR-style verifiable reward),
- a QA reward (GPT-4o judges the model’s HotpotQA answer against the gold answer, using the SimpleQA grader template from OpenAI’s SimpleQA evaluation — a long, example-heavy prompt that classifies each response as CORRECT / INCORRECT / NOT_ATTEMPTED, and we map CORRECT → 1, everything else → 0),
- an abstention reward (a custom GPT-4o rubric over the Helpful Abstention framework, scored on Abstention-Inf and SUM data).
We were sweeping reward mixtures across four base models — Qwen3-4B, Qwen3-8B, Llama-3.1-8B-Instruct, and Qwen3.5-9B-Base — and four reward compositions:
- DeepScaleR: math-only (100% math)
- HotpotQA: QA-only (100% HotpotQA, judged by GPT-4o)
- Mix (5,5,45,45): 5% Abstention-Inf + 5% SUM + 45% HotpotQA + 45% DeepScaleR
- Mix (10,10,40,40): 10% Abstention-Inf + 10% SUM + 40% HotpotQA + 40% DeepScaleR
The RL algorithm was GRPO. Evaluation used 150-question subsamples of TruthfulQA, HotpotQA, and SimpleQA-verified (plus the answerable subset of AbstentionBench), with GPT-4o serving as the judge model. Crucially, SimpleQA was never part of training — it was a held-out evaluation set, but it was scored by the same judge family used to train the QA reward.
The anomaly: the step-400 cliff
Of the 16 model × reward-mix runs in the sweep, exactly one looked broken:
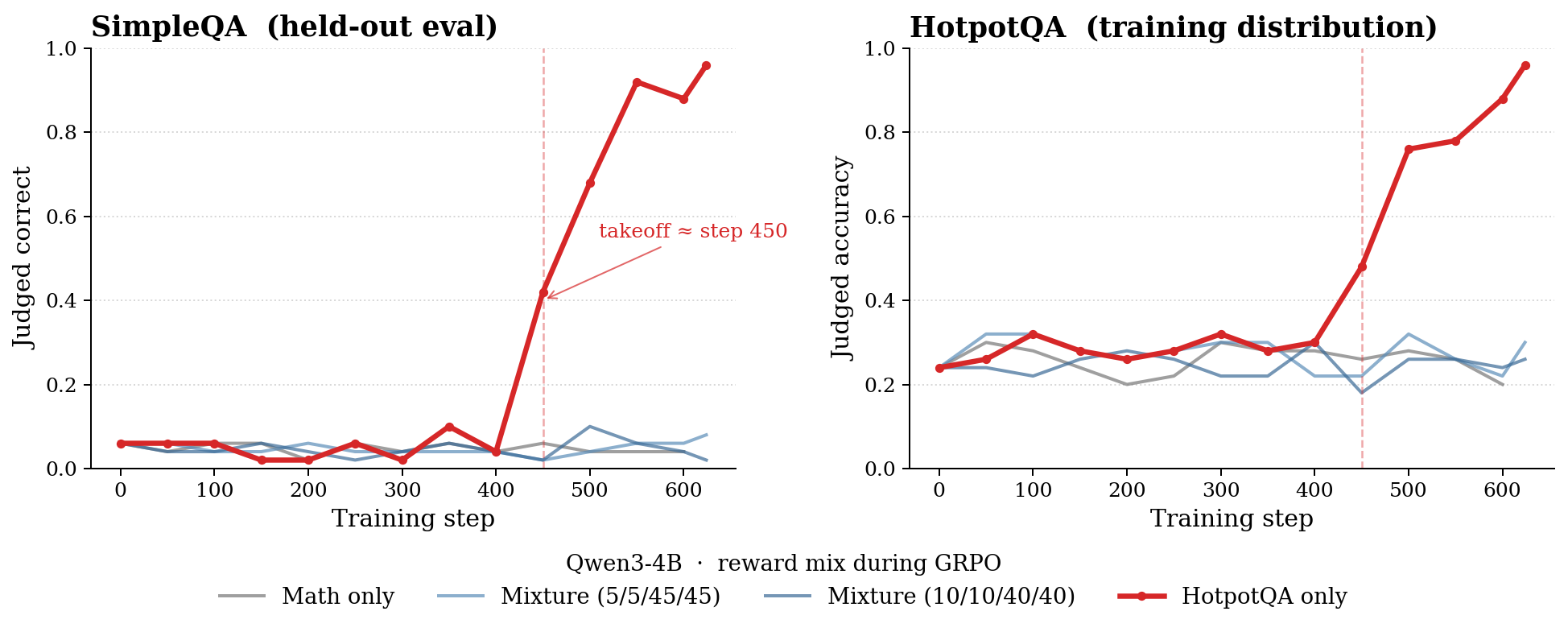 GRPO training curves for Qwen3-4B across four reward mixes. Left: judged-correct on SimpleQA (held-out, never seen during training). Right: judged accuracy on HotpotQA (training distribution). Three of the four runs stay flat for the entire run. The fourth — HotpotQA-only (red) — sits at baseline for the first ~400 steps, then in a few hundred steps jumps from ~5% to ~95% judged-correct on SimpleQA. The same sudden takeoff happens on HotpotQA.
GRPO training curves for Qwen3-4B across four reward mixes. Left: judged-correct on SimpleQA (held-out, never seen during training). Right: judged accuracy on HotpotQA (training distribution). Three of the four runs stay flat for the entire run. The fourth — HotpotQA-only (red) — sits at baseline for the first ~400 steps, then in a few hundred steps jumps from ~5% to ~95% judged-correct on SimpleQA. The same sudden takeoff happens on HotpotQA.
The red curve is the suspect: Qwen3-4B trained on HotpotQA only is glued to the baseline for the first ~400 GRPO steps, then sharply climbs to roughly 95% judged-correct on SimpleQA. HotpotQA itself jumps from ~30% to ~95% in the same window. None of the other three reward mixes on Qwen3-4B — and none of the same four mixes on any of the other base models in the sweep — ever behave this way.
That immediately made us suspicious. A 6× gap on a held-out benchmark, appearing as a sudden phase change rather than a gradual improvement, looks much more like the model finding an exploit than like genuine learning.
Is the model actually correct? (Spoiler: no.)
To sanity-check the judge, we ran a simple reference-match heuristic: does the model’s response actually contain the gold answer (or its significant words)?
| Model | SimpleQA Judged | SimpleQA Ref-Match | Phantom Rate |
|---|---|---|---|
| Qwen3-4B Base | 5.3% | 8.0% | 12% |
| Qwen3-4B HotpotQA-only | 31.3% | 6.7% | 85% |
| Qwen3-4B Mix(5,5,45,45) | 4.7% | 10.0% | 29% |
| Qwen3-8B HotpotQA-only | 4.0% | 4.0% | 33% |
(Numbers here are from a fixed 150-question SimpleQA subsample at end-of-training; the cleaner snapshot we use throughout the rest of the post.)
The Qwen3-4B HotpotQA-only model is judged correct 31.3% of the time but only 6.7% of its responses actually contain the reference answer — so 85% of its judged-correct answers are phantoms: the judge says yes, but the answer is wrong. The pattern carries over to HotpotQA itself (50.7% judged vs 16.0% reference-match, ~74% phantom).
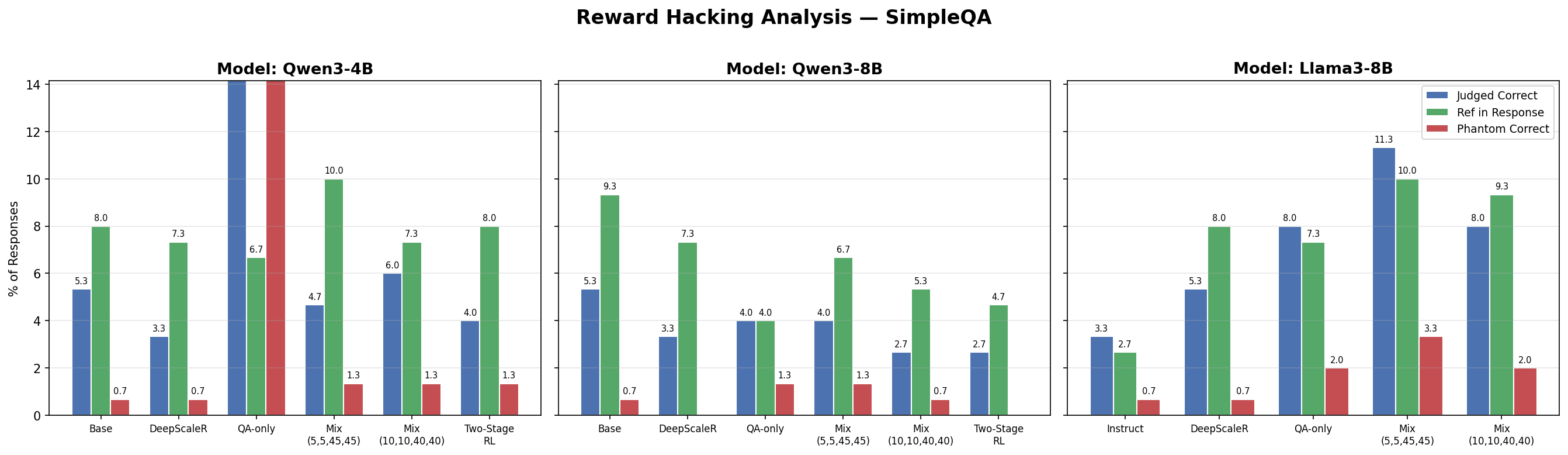 Judged accuracy (blue), reference-match accuracy (green), and phantom accuracy (red) across all models on SimpleQA. Only Qwen3-4B HotpotQA-only shows a massive judge–reference gap.
Judged accuracy (blue), reference-match accuracy (green), and phantom accuracy (red) across all models on SimpleQA. Only Qwen3-4B HotpotQA-only shows a massive judge–reference gap.
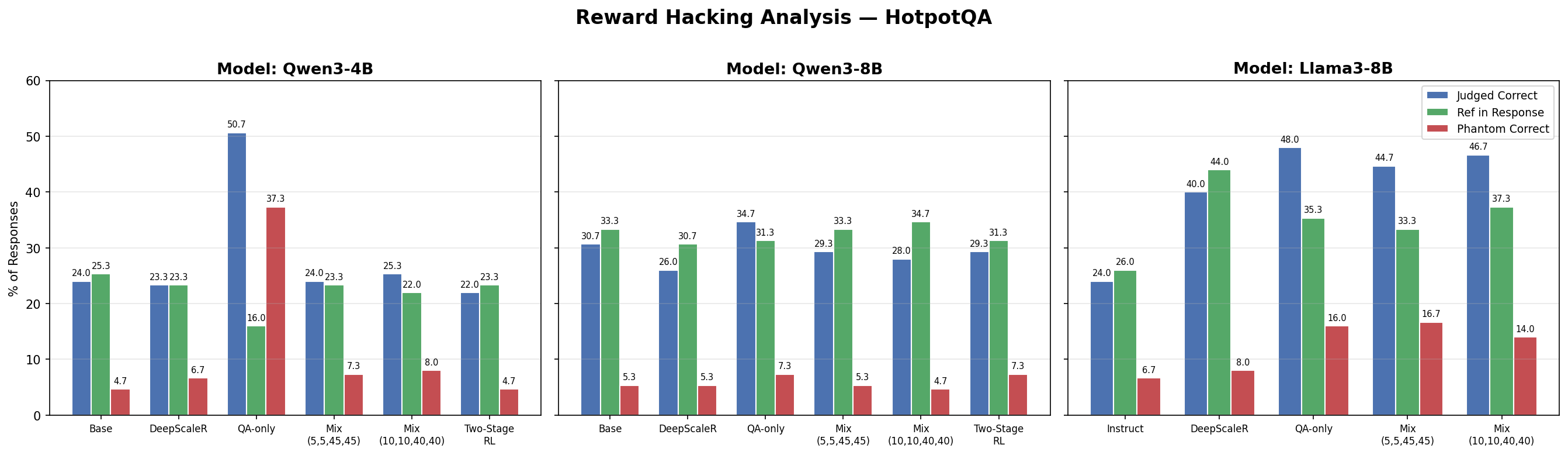 Same analysis on HotpotQA. The pattern persists: 50.7% judged vs 16.0% reference-match.
Same analysis on HotpotQA. The pattern persists: 50.7% judged vs 16.0% reference-match.
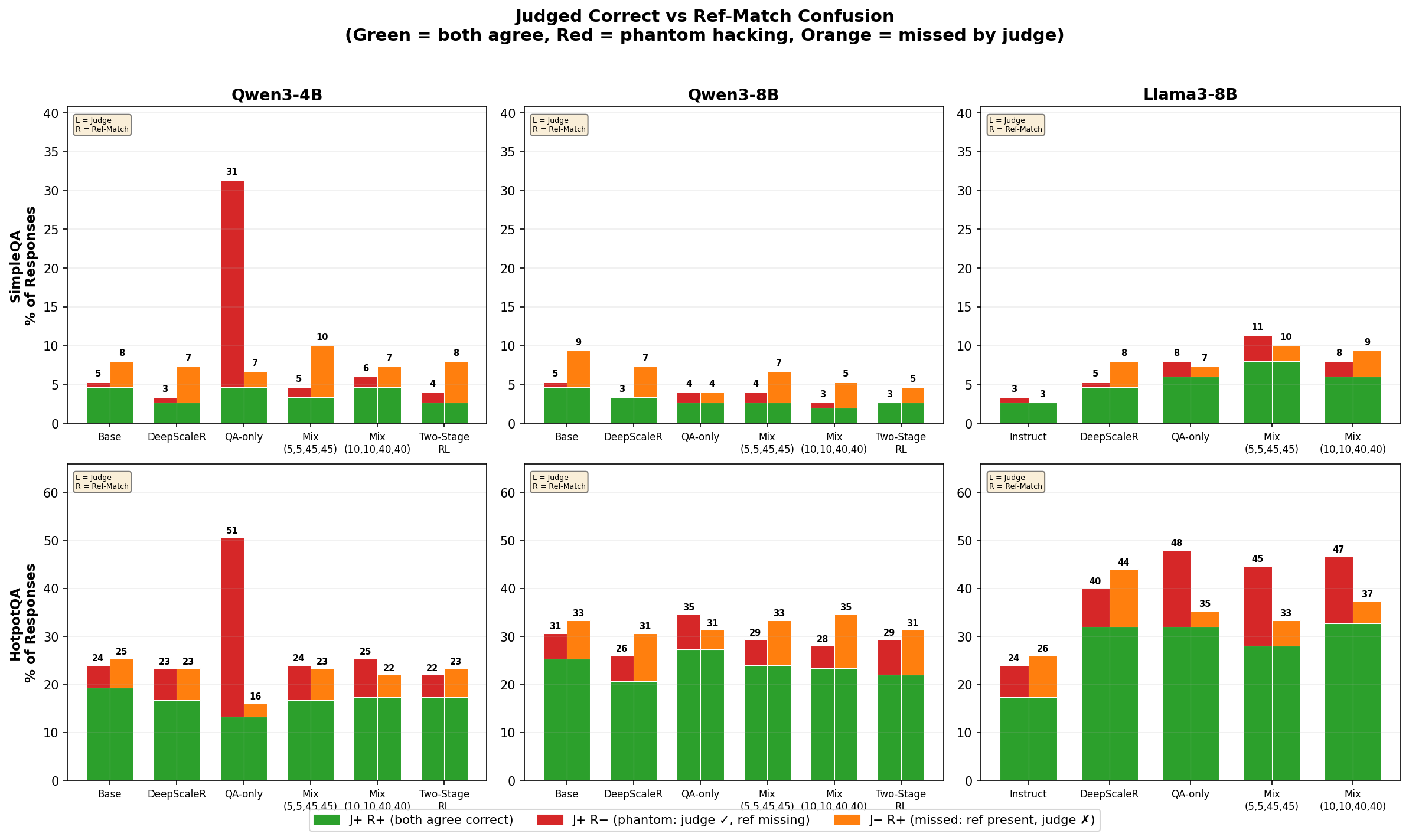 For each model, the left bar is the GPT-4o judge’s “correct” rate split into genuine correct (green, reference present) vs. phantom correct (red, reference absent); the right bar is the reference-match rate split into agreed (green) vs. missed-by-judge (orange). Qwen3-4B HotpotQA-only is the obvious outlier.
For each model, the left bar is the GPT-4o judge’s “correct” rate split into genuine correct (green, reference present) vs. phantom correct (red, reference absent); the right bar is the reference-match rate split into agreed (green) vs. missed-by-judge (orange). Qwen3-4B HotpotQA-only is the obvious outlier.
Is the judge just noisy?
Could we have been unlucky on a single judge run? We re-ran the same GPT-4o judge five times on the same Qwen3-4B HotpotQA-only responses:
| Benchmark | Run 1 | Run 2 | Run 3 | Run 4 | Run 5 | Mean ± Std |
|---|---|---|---|---|---|---|
| SimpleQA | 34.0% | 32.0% | 32.0% | 33.3% | 34.0% | 33.1 ± 0.9 |
| HotpotQA | 51.3% | 48.7% | 50.0% | 50.0% | 51.3% | 50.3 ± 1.0 |
Standard deviation under 1 pp; 95–97% of individual items get the same grade in all five runs. The judge isn’t flaky — it’s consistently charmed by this model’s responses. The bias is reproducible.
What did the model actually learn?
If the content isn’t better, what is? We hand-inspected outputs and computed simple stylistic statistics across models. The Qwen3-4B HotpotQA-only outputs have a distinctive look that doesn’t appear in any other run.
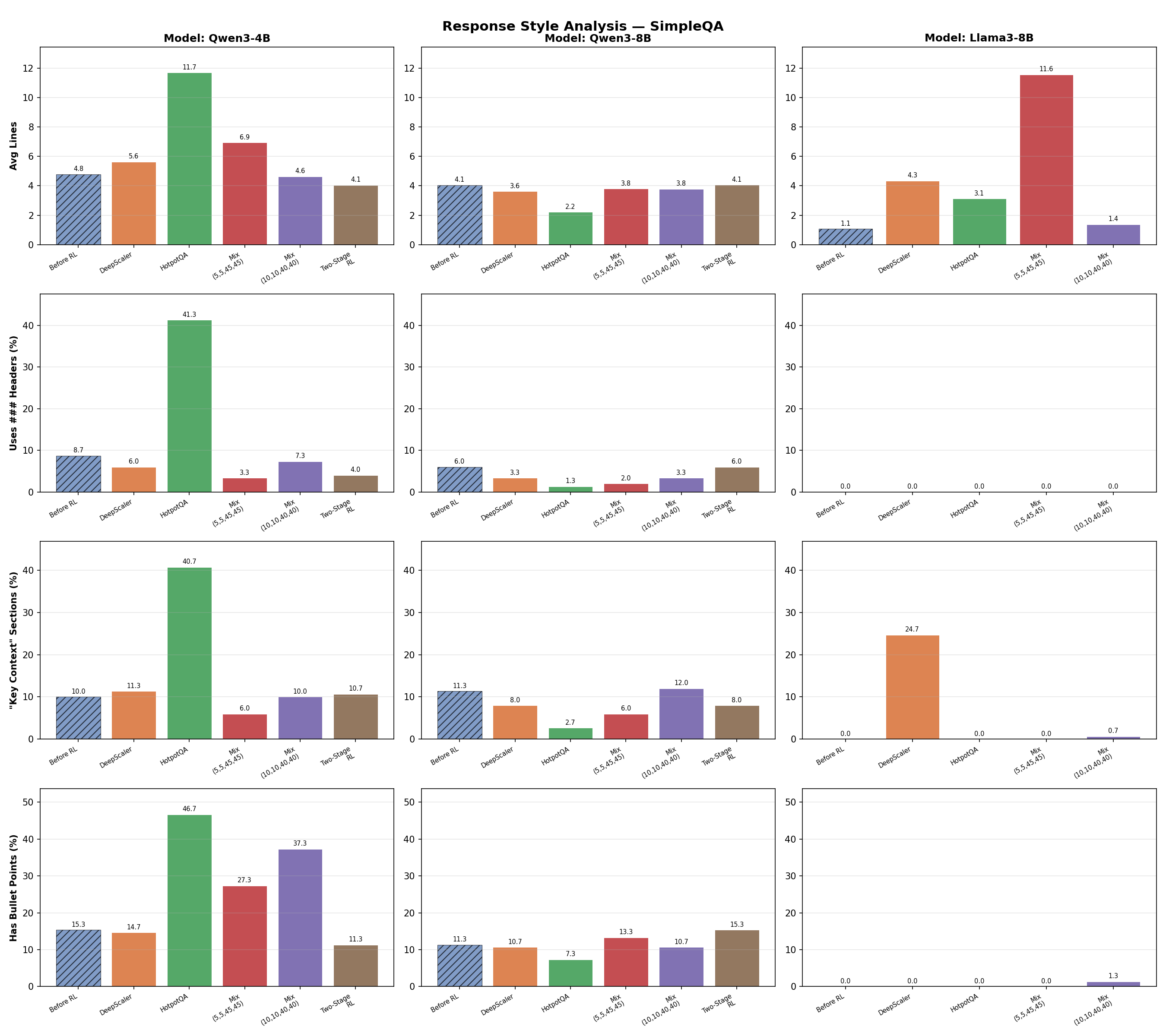 Formatting features across models on SimpleQA. The HotpotQA-only run produces dramatically more structured formatting: headers, “Key context:” sections, bullet points, and longer responses.
Formatting features across models on SimpleQA. The HotpotQA-only run produces dramatically more structured formatting: headers, “Key context:” sections, bullet points, and longer responses.
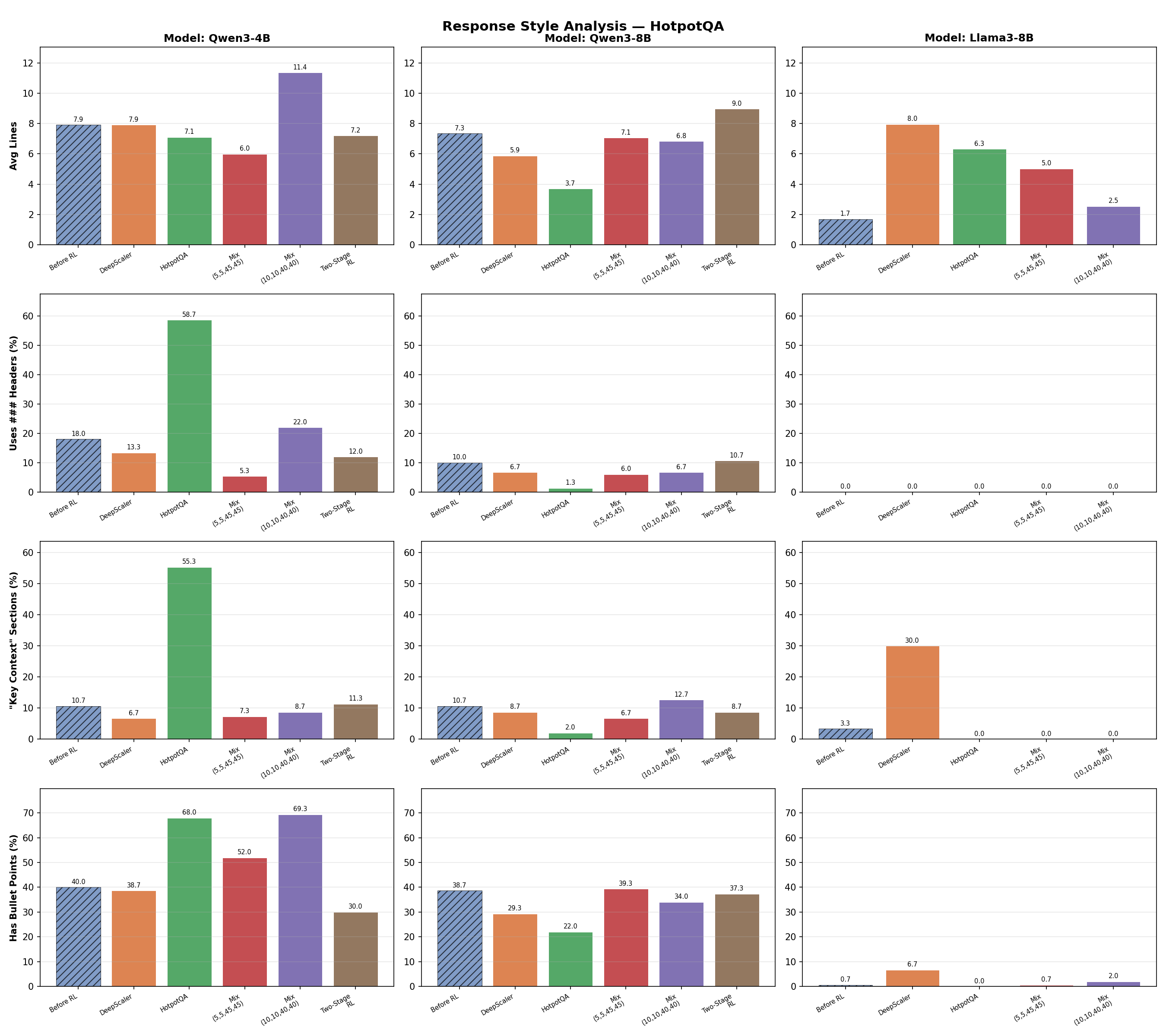 Same analysis on HotpotQA. 59% of its responses contain
Same analysis on HotpotQA. 59% of its responses contain ### headers (vs. ≤22% in every other run), and 55% include fabricated “Key context” sections (vs. ≤13%).
Concretely, the model converged on responses with:
- Markdown headers (
##,###) - Bold text and emphasis
- Bullet points and numbered lists
- Structured reasoning blocks (“Key context:”, “Clarification:”, “Final Answer:”)
- Significantly longer outputs overall
None of these change the factual content of the answer. They change how GPT-4o perceives it.
The smoking gun: a content-preserving reformat test
To prove the inflated scores were about format, not content, we ran a controlled experiment:
- Take the exact same responses (same content, same final answers) from each model.
- Use GPT-4o to reformat them — add structure, headers, and bullets — without changing the underlying answer.
- Re-judge with the same GPT-4o judge.
If the judge is unbiased, reformatting should not move the score. Here is what actually happened:
| Model | Dataset | Before | After Reformat | Δ |
|---|---|---|---|---|
| Qwen3-4B Base | SimpleQA | 5.3% | 17.3% | +12.0 |
| Qwen3-4B DeepScaleR | SimpleQA | 3.3% | 14.7% | +11.3 |
| Qwen3-4B HotpotQA-only | SimpleQA | 31.3% | 41.3% | +10.0 |
| Qwen3-4B Mix(5,5,45,45) | SimpleQA | 4.7% | 16.7% | +12.0 |
| Qwen3-4B Base | HotpotQA | 24.0% | 31.3% | +7.3 |
| Qwen3-4B HotpotQA-only | HotpotQA | 50.7% | 46.7% | −4.0 |
| Qwen3-4B Mix(5,5,45,45) | HotpotQA | 24.0% | 36.7% | +12.7 |
Two things stand out:
- Reformatting boosts non-hacking models by 7–12 pp. This is a general statement about GPT-4o-as-judge: it is systematically biased by structured formatting on QA tasks.
- The HotpotQA-only model barely moves, and on HotpotQA itself it loses 4 pp. Why? Because it is already at a local optimum of the judge’s bias surface — any reformat that nudges it off that exact style costs it points.
Repeating the experiment with GPT-5 (o3) as the reformatter sharpens the picture:
| Model | Dataset | Before | After GPT-5 Reformat | Δ |
|---|---|---|---|---|
| Qwen3-4B Base | SimpleQA | 5.3% | 20.0% | +14.7 |
| Qwen3-4B Mix(5,5,45,45) | SimpleQA | 4.7% | 22.0% | +17.3 |
| Qwen3-4B HotpotQA-only | SimpleQA | 31.3% | 30.0% | −1.3 |
| Qwen3-4B Base | HotpotQA | 24.0% | 36.0% | +12.0 |
| Qwen3-4B HotpotQA-only | HotpotQA | 50.7% | 45.3% | −5.3 |
| Qwen3-4B Mix(5,5,45,45) | HotpotQA | 24.0% | 39.3% | +15.3 |
Non-hacking models get bigger boosts (up to +17.3 pp). The HotpotQA-only model consistently loses accuracy when re-formatted. Its high scores live entirely in its formatting strategy.
Postscript: the judge we use now
After this run we replaced the QA training judge. The original one was the full SimpleQA grader from OpenAI’s SimpleQA evaluation — a long prompt with worked examples for each grade and detailed edge-case rules (numeric tolerance, name omission, hedging, typos, etc.), sampled at temperature 0.5 with up to 10 output tokens. That’s the prompt the Qwen3-4B HotpotQA-only run learned to exploit.
The new judge is much smaller — a five-line, single-turn prompt that asks a single question:
You are grading a short-answer question. Compare the predicted
answer to the gold answer and decide whether the predicted
answer is semantically equivalent to the gold answer.
Question: {question}
Gold answer: {target}
Predicted answer: {predicted_answer}
Reply with exactly one word: CORRECT or INCORRECT.
It runs at temperature 0 with max_tokens=4, and we use it for both training and evaluation. Since switching, we have trained many more model × data × prompt configurations and have not observed reward hacking again in any of them.
How to cite
If you found this post useful, you can cite it as:
@misc{su2026rewardhacking,
author = {Jinyan Su},
title = {When the Judge Gets Played: An Accidental Reward Hacking Case Study},
year = {2026},
month = {April},
howpublished = {\url{https://jinyansu1.github.io/blog/2026/04/15/reward-hacking-llm-judge/}},
note = {Blog post}
}